
Introduction
Artificial Intelligence (AI) and Machine Learning (ML) teach computers to learn patterns from data.
For example, an AI model can learn to recognise handwritten numbers, detect spam emails, predict customer behaviour, recommend products, or identify objects in images. But building the model is only one part of the process.
The important question is:
How do we know if the model actually works well?
A model may perform well during training, but that does not always mean it will work well in the real world. Sometimes, it only looks accurate because it has memorised the training data. When it sees new data, its performance drops.
This is called overfitting.
To avoid being misled by high training scores, data scientists use evaluation methods that test how well a model performs on unseen data. One common method is cross-validation, more specifically, the 10-Fold Cross-Validation. It helps check whether a model is truly learning useful patterns or simply memorising answers. This is especially useful for neural networks, because they are powerful models that can overfit if not tested carefully.
What Is 10-Fold Cross-Validation?

10-Fold Cross-Validation is a method used to test a machine learning model more fairly.Instead of splitting the data once into a training set and a testing set, the dataset is split into 10 equal parts, called folds.
The model is trained and tested 10 times.
Each time:
- 9 folds are used to train the model
- 1 fold is used to test the model
- A different fold is used for testing in each round
After all 10 rounds, the results are averaged to produce one final performance score.
In simple terms:
Train on 9 parts, test on 1 part, repeat 10 times, then average the results.
This gives a more reliable estimate of how the model will perform on new, unseen data.
Why Cross-Validation Is Needed
Many beginners use a simple train-test split, such as:
- 80% training data
- 20% testing data
This is easy to understand, but the result depends heavily on how the data is split. If the testing set is too easy, the model may look better than it really is. If the testing set is too difficult, the model may look worse than it really is.10-Fold Cross-Validation reduces this problem because the model is tested on 10 different parts of the dataset instead of only one, making the evaluation more stable and trustworthy.
A Simple Example
Imagine you have 10,000 images and want to train an AI model to classify them.
With 10-Fold Cross-Validation:
- The dataset is split into 10 folds
- Each fold has 1,000 images
- Each round uses 9,000 images for training
- Each round uses 1,000 images for testing
|
Round |
Training Data |
Testing Data |
|
1 |
Folds 1–9 |
Fold 10 |
|
2 |
Folds 1–8 and 10 |
Fold 9 |
|
3 |
All except Fold 8 |
Fold 8 |
|
4 |
All except Fold 7 |
Fold 7 |
|
5 |
All except Fold 6 |
Fold 6 |
|
6 |
All except Fold 5 |
Fold 5 |
|
7 |
All except Fold 4 |
Fold 4 |
|
8 |
All except Fold 3 |
Fold 3 |
|
9 |
All except Fold 2 |
Fold 2 |
|
10 |
Folds 2–10 |
Fold 1 |
By the end, every fold has been used as testing data once.
Why This Matters for AI Models?
It matters for AI models as the real goal of machine learning is not to perform well on training data, it is to perform well on new data. This is called generalisation. Generalisation means the model can apply what it has learned to examples it has never seen before.
For example:
- A handwriting recognition model should recognise handwriting from new people
- A fraud detection model should detect new fraud attempts
- A medical image model should work on new patient scans
- A recommendation system should adapt to new customer behaviour
A model that performs well only on training data is not useful in the real world. 10-Fold Cross-Validation helps estimate whether the model can generalise properly.
What Is a Neural Network?
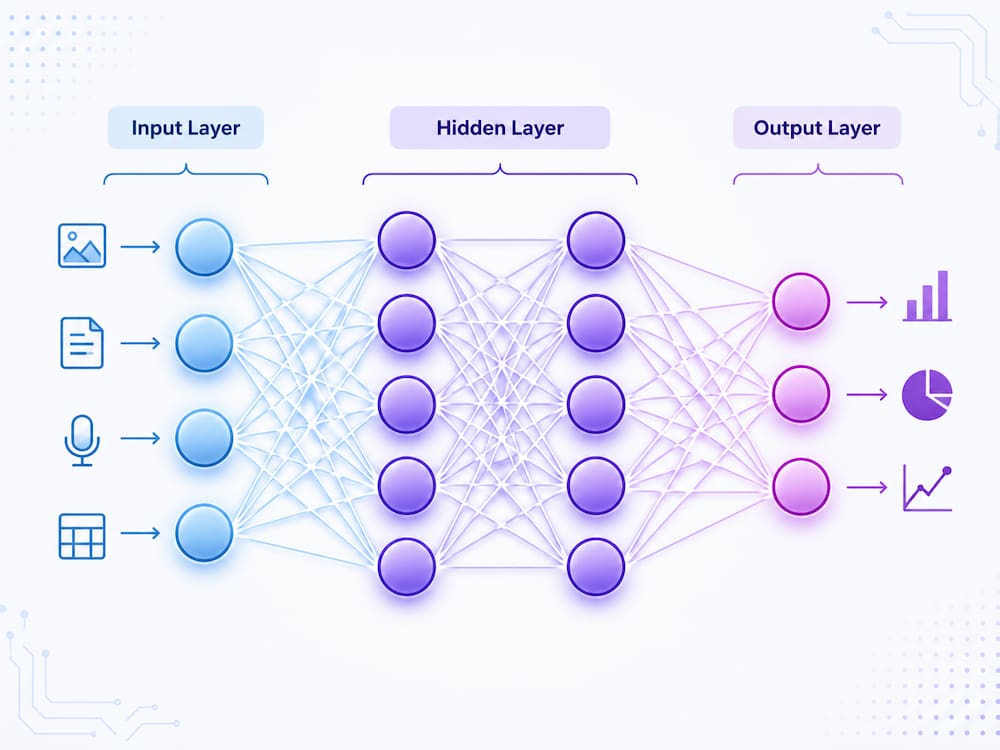
A neural network is a type of machine learning model inspired by how the human brain works. It is made up of layers of connected units called neurons. These neurons process information and learn patterns from data.
|
Part |
What It Does |
|
Input Layer |
Receives the data |
|
Hidden Layers |
Learn patterns from the data |
|
Output Layer |
Produces the prediction |
Neural networks are used for image recognition, speech recognition, text classification, fraud detection, forecasting, recommendation systems, and medical diagnosis support. They are powerful because they can learn complex patterns, but this also means they must be evaluated carefully.
Why Neural Networks Need Careful Testing
Neural networks can learn very detailed patterns from data. This is useful, but it can become a problem if the model starts memorising instead of learning. For example, imagine you are training a model to recognise cats. A good model should learn general cat features, such as ears, eyes, fur, face shape, and body shape. An overfitted model may accidentally learn irrelevant details, such as the background colour, camera angle, lighting, or furniture behind the cat.If the model sees a new cat image with a different background, it may fail.
10-Fold Cross-Validation helps detect this because the model is tested repeatedly on data it has not seen during training.
Why Use 10 Folds?
The number 10 is popular because it gives a good balance between reliability and efficiency.
With 10 folds:
- 90% of the data is used for training in each round
- 10% of the data is used for testing in each round
- The model is evaluated 10 times
- The final score is based on an average
|
Method |
Training Data per Round |
Testing Data per Round |
Reliability |
Speed |
|
5-Fold Cross-Validation |
80% |
20% |
Good |
Faster |
|
10-Fold Cross-Validation |
90% |
10% |
Strong |
Balanced |
|
20-Fold Cross-Validation |
95% |
5% |
Very strong |
Slower |
For many machine learning projects, 10 folds are a practical middle ground.
Training Set, Validation Set, and Test Set
Beginners often confuse training, validation, and testing.
|
Dataset Type |
Purpose |
|
Training Set |
Used to teach the model |
|
Validation Set |
Used to check performance during development |
|
Test Set |
Used for final evaluation after development |
In 10-Fold Cross-Validation, each fold takes turns acting as the validation set.
In professional projects, developers may still keep a final separate test set. This final test set is used only once at the end, after all tuning is complete.
A good workflow is:
- Keep a final test set aside
- Use 10-Fold Cross-Validation on the training data
- Choose the best model or settings
- Evaluate once on the final test set
Random K-Fold vs Stratified K-Fold

There are two common ways to split data into folds: Random K-Fold and Stratified K-Fold.
Random K-Fold
Random K-Fold splits the dataset randomly into folds. This works well when the dataset is balanced.For example, if your dataset contains 50% cat images and 50% dog images, random splitting is likely to produce fair folds.
Stratified K-Fold
Stratified K-Fold keeps the class distribution similar in every fold.For example, if your dataset contains 80% cats and 20% dogs, Stratified K-Fold tries to make sure each fold also contains roughly 80% cats and 20% dogs.
|
Method |
Best For |
Advantage |
Risk |
|
Random K-Fold |
Balanced datasets |
Simple and fast |
May create uneven class distribution |
|
Stratified K-Fold |
Imbalanced classification datasets |
Keeps class ratios consistent |
Slightly more complex |
For most classification problems, Stratified K-Fold is often the safer choice.
What is Class Balance & why it Matters
Class balance refers to the relative distribution of examples among different classes with a dataset. A dataset is considered imbalanced when one class(the majority) significantly outweighs the other(the minority)
Class balance matters because a model can appear accurate while still performing badly on minority classes.
For example, in a fraud detection dataset:
- 99% normal transactions
- 1% fraud transactions
A model could predict “normal” every time and still get 99% accuracy. But it would be useless because it fails to detect fraud.This is why accuracy alone can be misleading in imbalanced datasets. Stratified K-Fold helps by making sure each fold contains a fair proportion of each class.
What Is KFold in Scikit-Learn?
In Python, many developers use Scikit-Learn to perform cross-validation.
A common KFold setup looks like this:
KFold(n_splits=10, shuffle=True, random_state=42)
Setting | Meaning |
|
n_splits=10 |
Splits the dataset into 10 folds |
|
shuffle=True |
Randomly mixes the data before splitting |
|
random_state=42 |
Makes the split reproducible |
shuffle=True helps prevent biased folds when data is ordered.
random_state=42 helps make results repeatable, which is useful when comparing models, debugging, or writing reports.
How to Implement 10-Fold Cross-Validation in Neural Networks
To implement 10-Fold Cross-Validation with neural networks, developers often combine:
- Scikit-Learn for splitting data
- TensorFlow or Keras for building the neural network
- NumPy or Pandas for data handling
- Metrics tools for evaluation
The general workflow is:
- Load the dataset
- Preprocess the data
- Create the 10-fold splitter
- Loop through each fold
- Build a fresh neural network model
- Train the model on 9 folds
- Validate the model on 1 fold
- Store the result
- Repeat for all 10 folds
- Average the results
The most important rule is:
Use a fresh model for every fold.
Why You Must Use a Fresh Model Each Fold
A neural network learns by adjusting internal values called weights.
If you train a model on Fold 1, those weights change. If you then continue training the same model on Fold 2, the model carries knowledge from the previous fold.
This breaks the purpose of cross-validation.
Each fold should be treated as a separate experiment. If you reuse the same model, your results may become falsely high because the model has indirectly learned from data it should not have seen.
This is a form of data leakage.
Basic Neural Network Terms Explained
|
Term |
Simple Meaning |
|
Sequential Model |
A neural network built layer by layer |
|
Dense Layer |
A layer where each neuron connects to neurons in the next layer |
|
ReLU Activation |
A function that helps the model learn complex patterns |
|
Output Layer |
The final layer that produces the prediction |
|
Adam Optimizer |
A method that helps the model improve during training |
|
Loss Function |
Measures how wrong the model’s predictions are |
|
Epoch |
One full pass through the training data |
|
Batch Size |
Number of samples processed before the model updates itself |
These terms describe how the neural network learns and improves.
Step-by-Step Methodology
Step 1: Import the Required Libraries
You need tools for splitting data, building the model, training the model, and evaluating results.
Scikit-Learn handles fold splitting, while TensorFlow and Keras handle the neural network.
Step 2: Load the Dataset
For beginner projects, MNIST is often used because it is simple and widely known. Each MNIST image is 28 by 28 pixels, which means each image contains 784 pixel values. For a basic neural network, the image can be reshaped from a 28×28 grid into a flat list of 784 numbers.
Step 3: Preprocess the Data
Preprocessing means preparing the data before training.
Common preprocessing steps include:
- Reshaping images
- Scaling numerical values
- Normalising pixel values
- Encoding labels
- Removing missing values
For image data, pixel values usually range from 0 to 255. Scaling them to a smaller range, such as 0 to 1, helps the neural network learn more smoothly.
What Is Data Leakage?
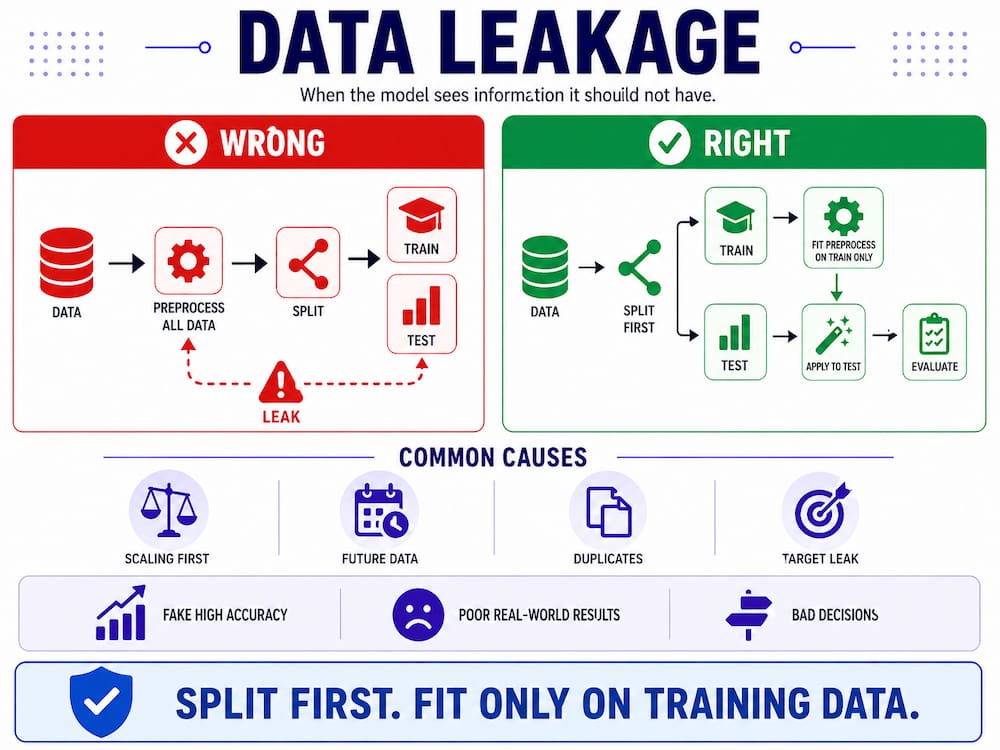
Data leakage happens when information from validation or test data accidentally influences the training process.
This makes the model look better than it actually is.For example, if you normalise the entire dataset before splitting it into folds, the validation data helps calculate the scaling values. This means the validation fold is no longer fully unseen.
The correct approach is:
- Split the data into training and validation folds
- Fit preprocessing tools only on the training fold
- Apply the same transformation to the validation fold
- Train and evaluate the model
This keeps validation data honest.
Step 4: Define the Neural Network Model
For a simple MNIST classification task, a neural network may include:
- An input layer
- One or more Dense hidden layers
- ReLU activation
- An output layer with 10 neurons
- Softmax activation for class probabilities
The output layer has 10 neurons because there are 10 possible classes: digits 0 to 9. The model is then compiled using an optimizer such as Adam, a loss function such as sparse categorical crossentropy, and a metric such as accuracy.
Step 5: Train and Analyse Across Folds
For each fold:
- Select 9 folds as training data
- Select 1 fold as validation data
- Create a fresh neural network
- Train the model
- Evaluate the model on the validation fold
- Save the accuracy and loss
- Move to the next fold
After all folds are complete, look at:
- Average accuracy
- Average loss
- Best fold score
- Worst fold score
- Standard deviation
- Variance across folds
The average score tells you expected performance. The standard deviation tells you how consistent the model is.
What Metrics Should You Track?
Accuracy is useful, but it is not always enough.
Metric | What It Tells You |
|
Accuracy |
Percentage of correct predictions |
|
Loss |
How wrong the model’s predictions are |
|
Validation Accuracy |
Performance on unseen fold data |
|
Precision |
How often positive predictions are correct |
|
Recall |
How many true positive cases the model catches |
|
F1 Score |
Balance between precision and recall |
|
Fold Variance |
How consistent the model is across folds |
For balanced datasets, accuracy may be enough.
For imbalanced datasets, such as fraud detection or disease prediction, precision, recall, and F1 score are often more useful.
Stable vs Unstable Fold Results
A stable model produces similar scores across folds.
Fold | Stable Model Accuracy | Unstable Model Accuracy |
|
1 |
95.1% |
98.0% |
|
2 |
94.8% |
86.5% |
|
3 |
95.0% |
93.0% |
|
4 |
95.2% |
79.2% |
|
5 |
94.9% |
97.1% |
|
6 |
95.3% |
88.4% |
|
7 |
95.1% |
95.6% |
|
8 |
94.7% |
82.0% |
|
9 |
95.0% |
96.8% |
|
10 |
95.2% |
90.1% |
The stable model is more reliable because its scores are close together. The unstable model changes too much between folds, which suggests it may not generalise consistently.
Training Accuracy vs Validation Accuracy
Training accuracy shows how well the model performs on data it has already seen.
Validation accuracy shows how well the model performs on unseen data.
Validation accuracy is more important.
|
Situation |
Training Accuracy |
Validation Accuracy |
Meaning |
|
Overfitting |
99% |
82% |
Model memorised training data |
|
Better generalisation |
94% |
92% |
Model is more reliable |
A smaller gap between training and validation accuracy usually means the model generalises better.
Early Stopping in Neural Networks
Neural networks can overtrain if they run for too many epochs.At first, training usually improves both training and validation performance. But after some time, the model may continue improving on training data while getting worse on validation data.This means the model is starting to memorise.
Early stopping helps prevent this by stopping training when validation performance stops improving.This helps reduce overfitting, save training time, improve generalisation, and avoid unnecessary computation.
Common Pitfalls in 10-Fold Cross-Validation
|
Mistake |
Why It Is a Problem |
|
Not shuffling data |
Ordered data can create biased folds |
|
Reusing the same model |
The model carries knowledge from earlier folds |
|
Preprocessing before splitting |
Validation data may influence training |
|
Ignoring class imbalance |
Some folds may not represent minority classes fairly |
|
Looking only at accuracy |
Accuracy can be misleading |
|
Training for too many epochs |
The model may overfit |
|
Ignoring fold variance |
The model may be unstable |
Avoiding these mistakes helps keep validation results honest.
When 10-Fold Cross-Validation May Not Be the Best Choice
10-Fold Cross-Validation is useful, but not always ideal.
|
Situation |
Better Alternative |
|
Very large datasets |
Train-validation-test split |
|
Time-series data |
Time-series validation |
|
Expensive deep learning models |
Fewer folds or holdout validation |
|
Grouped data |
Grouped cross-validation |
For example, if a neural network takes several hours to train once, training it 10 times may be impractical.
How It Fits Into AI Workflow Automation
In real AI projects, cross-validation is part of a larger workflow:
- Collect data
- Clean data
- Preprocess data
- Split data
- Train models
- Validate models
- Tune hyperparameters
- Choose the best model
- Test the final model
- Deploy and monitor performance
10-Fold Cross-Validation usually happens during model validation and tuning.It helps teams decide whether a model is reliable enough to move forward.
Real-World Examples
|
Industry |
How Cross-Validation Helps |
|
Finance |
Tests fraud detection and credit risk models |
|
Healthcare |
Checks whether medical AI works across patient groups |
|
Marketing |
Tests churn prediction and campaign response models |
|
Retail |
Compares recommendation and demand forecasting models |
|
Cybersecurity |
Tests suspicious activity detection systems |
In each case, the goal is the same: make sure the model works on new data, not just past examples.
10-Fold Cross-Validation and Hyperparameter Tuning
Hyperparameters are settings chosen before training begins.
Examples include:
- Number of epochs
- Batch size
- Learning rate
- Number of hidden layers
- Number of neurons
- Dropout rate
- Optimizer choice
10-Fold Cross-Validation helps compare these settings more fairly.
|
Model |
Learning Rate |
Hidden Layers |
Average CV Accuracy |
|
Model A |
0.001 |
2 |
94.8% |
|
Model B |
0.0005 |
3 |
95.2% |
If both models are tested using the same 10 folds, the comparison is more reliable.
Beginner-Friendly Summary
Here is the full idea in simple terms:
- Split the dataset into 10 parts
- Train the model using 9 parts
- Test the model using the remaining part
- Repeat this 10 times
- Make sure each part is tested once
- Record the result from each round
- Average the results
- Check whether the model performs consistently
A simple way to remember it is:
Train on 9, test on 1, repeat 10 times, then average the results.
Conclusion
10-Fold Cross-Validation is a practical way to check whether an AI model is truly ready for new data.A model should not be judged only by how well it performs on training data. Training data is familiar to the model. Real-world data is not.
By splitting the dataset into 10 parts, training on 9 parts, testing on 1 part, and repeating the process until every part has been tested, 10-Fold Cross-Validation gives a more honest view of model performance.
For beginners, the key idea is simple:
A good AI model should not just memorise. It should generalise.
10-Fold Cross-Validation helps reveal that difference.
Frequently Asked Questions
Is 10-Fold Cross-Validation only for neural networks?
No. It can be used for many machine learning models, including decision trees, random forests, support vector machines, logistic regression, and neural networks.
Is 10-Fold Cross-Validation always better than a train-test split?
Not always. It is usually more reliable, but it takes more time because the model must be trained 10 times.
Should I use KFold or StratifiedKFold?
Use KFold when your dataset is balanced. Use StratifiedKFold for classification tasks where class balance matters.
Why do we average the 10 results?
Some folds may be easier, while others may be harder. Averaging gives a more balanced final score.
Can 10-Fold Cross-Validation prevent overfitting?
It does not directly prevent overfitting, but it helps detect it. To reduce overfitting, use methods such as early stopping, dropout, regularisation, more data, or a simpler model.
Do I still need a final test set?
In many professional projects, yes. Cross-validation helps with model selection, while a final test set gives one last unbiased evaluation.
Key Takeaways
- 10-Fold Cross-Validation gives a more reliable result than one train-test split
- The dataset is split into 10 folds
- The model trains on 9 folds and tests on 1 fold
- Every fold gets tested once
- Neural networks should use a fresh model for every fold
- Stratified K-Fold is better for imbalanced classification datasets
- Data leakage must be avoided
- Validation accuracy matters more than training accuracy
- Fold variance shows whether the model is stable


